


When securing an AWS environment, one of the first tasks is configuring CloudTrail and ensuring that logs from various accounts within an organization are shipped to a centralized AWS security account.
Frequently, however, there are other log sources that I will want to monitor across the environment. These are logs generated by custom services and applications that have some impact on security - web server logs, syslogs, various security product logs, etc.
When I first attempted to do this, it wasn't obvious from the documentation how to properly configure a system that could ingest from multiple accounts and data sources, and consolidate everything in one place.
In this article, I'll walk through the setup I finally landed on to capture those logs in CloudWatch, ingest them into a security account with Kinesis, and store them in an S3 bucket for future use. Some of the architecture choices are forced by AWS policy for cross account access (Kinesis).
A full setup would likely also include a life-cycle policy (storing older logs in something like Glacier), and integration with an SIEM or log visualization tool. I have used the Splunk S3 integration for SIEM integrations from this setup, and Kibana with ElasticSearch as a separate output from Kinesis for these purposes in the past.
If you haven't seen the security VPC setup, I cover that in the first article in this series, advanced AWS security architecture.
Why would we want to set something like this up? It gives us a few key security benefits:
- Immutable logs from all assets in our infrastructure. Auditors, security analysts, and forensic investigators can have confidence that a compromised server does not mean compromised logs, even if an attacker takes over the root account of a VPC.
- One place to search all log data in the event of an incident.
- Single point to backup / archive for future potential needs, allowing storage cost optimizations.
- One integration point for downstream security systems such as SIEM or visualization tools.
Log Architecture
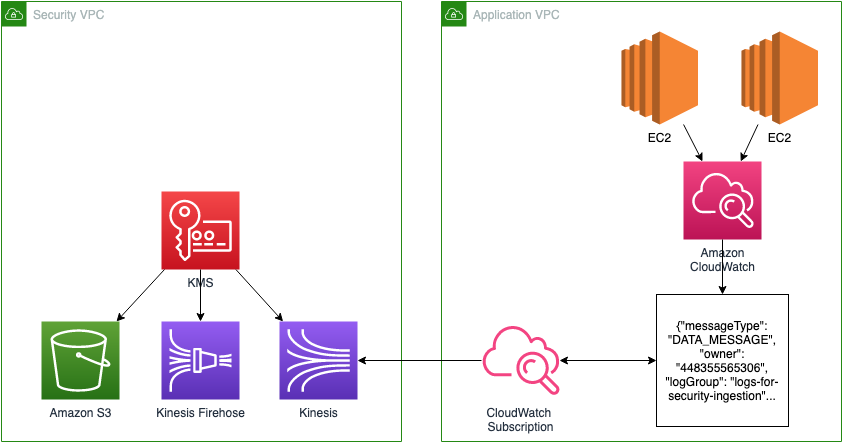
The setup in AWS is a little complicated, since our goal is to enable centralization from many application accounts to a single security account.
On the security side, we have a customer managed key (KMS) for encrypting everything end to end, with an S3 bucket as long term storage. To ingest and direct these logs, we need a Kinesis stream (to receive) and Kinesis Firehose (to direct to S3), along with some IAM roles and glue components.
On the application side, we need a smaller footprint: a subscription and a CloudWatch group to subscribe to. Any number of groups and/or subscriptions can be created here. the subscriptions also give us the capability of filtering logs to taget only those we care about, such as webserver logs or specially crafted security logs from applications.
CloudFormation
I created two cloud formation templates to provision all of this infrastructure. I'll walk through each major component here, or you can skip this part and go right to the full templates in github.
Required role & policy
We'll need a service role in the security account, and a policy that gives the minimum access needed to each service to ensure they can all communicate.
This role uses namespacing to give access only to the resources required. In this case, prefixing the assets with the name "secops-". In a real environment, you might use a unique ID from an asset system tied to an application.
IngestionRole:
Type: AWS::IAM::Role
Properties:
RoleName: security-log-writer
Path: /
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Action: sts:AssumeRole
Effect: Allow
Principal:
Service: !Sub "logs.${AWS::Region}.amazonaws.com"
- Action: sts:AssumeRole
Effect: Allow
Principal:
Service: firehose.amazonaws.com
Condition:
StringEquals:
sts:ExternalId: !Sub "${AWS::AccountId}"
IngestionRolePolicy:
Type: AWS::IAM::Policy
Properties:
PolicyName: security-log-writer-policy
Roles:
- !Ref IngestionRole
PolicyDocument:
Statement:
- Sid: KinesisReadWrite
Action:
- kinesis:Describe*
- kinesis:Get*
- kinesis:List*
- kinesis:Subscribe*
- kinesis:PutRecord
Effect: Allow
Resource: !Sub "arn:aws:kinesis:${AWS::Region}:${AWS::AccountId}:stream/secops-*" # Namespacing this role for things named secops
- Sid: S3ReadWrite
Action:
- s3:Get*
- s3:Put*
- s3:List*
Effect: Allow
Resource: # Namespace to assets starting with "secops"
- "arn:aws:s3:::secops-*"
- "arn:aws:s3:::secops-*/*"
- Sid: Passrole
Action:
- iam:PassRole
Effect: Allow
Resource: !GetAtt IngestionRole.Arn
KMS Encryption Key
We create a key that our role has complete access to. I also add the root user, and would recommend adding a security role for analysts in a real environment, or moving the logs into an analysis engine for consumption.
KMSKey:
Type: AWS::KMS::Key
Properties:
Description: Symmetric CMK
KeyPolicy:
Version: '2012-10-17'
Id: key-default-1
Statement:
- Sid: KeyOwner
Effect: Allow
Principal:
AWS: !Sub "arn:aws:iam::${AWS::AccountId}:root"
Action: kms:*
Resource: '*'
- Sid: KeyUser
Effect: Allow
Principal:
AWS: !GetAtt IngestionRole.Arn
Action: kms:*
S3 bucket & policy
An encrypted, non-public bucket and a locked down policy is all we need for this architecture. In a real enviornment, we would also want a data lifecycle policy to offload data to Glacier over time.
Here, I specify default AWS encryption, though a KMS key is preferred. Because logs are coming encrypted out of Kinesis already, they will actually land in the bucket encrypted with the KMS key anyway.
LogBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Ref LogBucketName
# Prevent public access
PublicAccessBlockConfiguration:
BlockPublicPolicy: True
BlockPublicAcls: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
# Encrypt the bucket - may also want to use KMS instead
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
LogBucketPolicy:
Type: AWS::S3::BucketPolicy
DependsOn: LogBucket
Properties:
Bucket: !Ref LogBucket
PolicyDocument:
Version: 2012-10-17
Statement:
- Action:
- S3:GetObject
- S3:PutObject
Effect: Allow
Resource: !Sub "arn:aws:s3:::${LogBucketName}/*"
Principal:
AWS: !GetAtt IngestionRole.Arn
Condition:
Bool:
aws:SecureTransport: True
Kinesis & Firehose
Finally, we setup an encrypted Kinesis instance and Firehose. This is a minimal configuration of Kinesis, suitable for a smaller ingestion load. As the system scales up, this setup will require tweaking for higher availability and throughput.
Stream:
Type: AWS::Kinesis::Stream
Properties:
Name: secops-SecurityLogStream
ShardCount: 1
StreamEncryption:
EncryptionType: KMS
KeyId: !Ref KMSKey
Firehose:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: secops-SecurityLogFirehose
DeliveryStreamType: KinesisStreamAsSource
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt Stream.Arn
RoleARN: !GetAtt IngestionRole.Arn
S3DestinationConfiguration:
BucketARN: !GetAtt LogBucket.Arn
BufferingHints:
IntervalInSeconds: 300
SizeInMBs: 5
CompressionFormat: GZIP
EncryptionConfiguration:
KMSEncryptionConfig:
AWSKMSKeyARN: !GetAtt KMSKey.Arn
RoleARN: !GetAtt IngestionRole.Arn
AWS Log Destination
Finally, we need to configure the destination that will be pointed at from the application accounts, and direct incoming logs to the stream. As of this writing, Destinations don't allow the normal policy attachment, making it difficult to include paramaters and references.
The solution I use is to create the policy inline with Join functions, which will allow us to reference parameters. Because we are doing cross account access, we have to specify which AWS accounts are allowed to write to our security account. Every time we add a new account, we will have to update this policy.
The format of the AppAccountIDs parameter is a comma separated string of account ID's
LogDestination:
Type: AWS::Logs::Destination
DependsOn: Stream
Properties:
DestinationName: SecurityLogDestination
DestinationPolicy:
!Join
- ''
- - '{'
- ' "Version" : "2012-10-17",'
- ' "Statement" : ['
- ' {'
- ' "Sid" : "",'
- ' "Effect" : "Allow",'
- ' "Principal" : {'
- ' "AWS" : ['
- !Ref AppAccountIDs
- ' ]'
- ' },'
- ' "Action" : "logs:PutSubscriptionFilter",'
- !Sub ' "Resource" : "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:destination:SecurityLogDestination"'
- ' }'
- ' ]'
- ' }'
RoleArn: !GetAtt IngestionRole.Arn
TargetArn: !GetAtt Stream.Arn
Generating Test Logs
I didn't cover the creation of a log group or subscription above, but you can see the templates in github (they are pretty simple). To run a test, I want to configure cloudwatch on an EC2 instance to send the messages logfile to the created group, then see if it makes its way to S3.
A good walkthrough of this setup process can be found on tensult's blog. The key item is to ensure that the awslogs process settings file has the proper group installed:
[/var/log/messages]
datetime_format = %b %d %H:%M:%S
file = /var/log/messages
buffer_duration = 5000
log_stream_name = {instance_id}
initial_position = start_of_file
log_group_name = logs-for-security-ingestion
You should immediately see logs flowing into CloudWatch, and within five or ten minutes, showing up in S3 as gzipped files.
Conclusions
Centralizing logs across many application accounts is more confusing than it probably should be. Moving the logs from S3 into another system frequently requires additional infrastructure and configurations. However, the security benefits of this are numerous, and it's probably worth doing as you scale up a larger business on AWS.
Unfortunately, all this infrastructure doesn't come free. Each component carries a cost (though I have not found it to be notable compared to what is monitored, with tight filters to scope down total logs ingested), and operational overhead.
I have not covered it here, but additional monitoring may be required to ensure that the log flow through these components is uninterrupted, and source logs are not being missed through missing subscriptions or improper CloudWatch agent setups.